Object Store for Large-scale Data Sharing
The GBSC Object Store is funded by National Institutes of Health (NIH) Office of Research Infrastructure Programs (ORIP). ORIP's S10 Programs support purchases of state-of-the-art commercially available instruments to enhance research of NIH–funded investigators.
The Genetics Bioinformatics Service Center manages an Object Store Server which was acquired via an NIH S10 Shared Instrumentation Grant. This object store is made available to the Stanford community for data sharing applications at no cost.
Data sharing is essential for the expedited translation of research results into knowledge, products, and procedures to improve human health, so researchers are under pressure from a variety of institutions to make their data available. Many scientific journals require that authors make available the data included in their papers as a condition of publication. Also, most NIH grant applications require that the investigators include a data-sharing plan, which encompasses all data from funded research that can be shared without compromising individual subjects' rights and privacy, regardless of whether the data have been used in a publication.
How does an object store work?
Object storage is a strategy that manages and manipulates data storage as distinct units called objects. These objects are kept in a single storehouse and are not organized as files inside other folders. This flat address space allows object storage to be almost infinitely scalable.
Also, object storage combines the pieces of data that make up a file and adds all its relevant metadata to an object containing the file, so all the information regarding a set of data can be accessed in one place. A real-life example of the value of metadata can be seen in how hospitals can store and process X-rays images of patients. An ordinary X-ray file would have limited metadata associated with it, such as created date, owner, location, and size. Any other metadata about such a file would have to be stored in some other place (e.g., another file or a database) and somehow associated with the X-ray image file. An X-ray object, on the other hand, could have a rich variety of metadata information attached to it, including patient name, date of birth, injury details, which area of the body was X-rayed – in addition to the same tags that the file had. This metadata makes it much easier for researchers to search for the X-rays that they need for a particular study.
Objects are shared via two main protocols: HTTP (like webpages) and S3 (the standard for cloud storage created by Amazon). HTTP sharing allows objects to be downloaded via browsers and URLs to the object store can be integrated into any website. S3 sharing allows the object store to interact seamlessly with cloud computing environments.
How can an object store can be used to share research data?
Public data repository sharing
With the ever-increasing amounts of scientific data that are being generated and that are required for discovery, more and more public data repositories are being established, and these data sources have become very valuable for many investigations. These sites gather together many different kinds of data about a particular domain and allow other researchers to access this information for their work.
What makes a data repository valuable is the metadata that is delivered with the files: data about the data. This metadata is critical to helping the downloading researcher decide if the data that is presented is relevant to the investigation that they are conducting, especially if that investigation is assembling data from multiple sources. For a FASTQ file from a sequencing run, the metadata referring to it might be the type of sequencer used, the date and time of the run, the read lengths performed, the organism sampled, the chemical concentrations measured, and the institution where the run was performed.
Sometimes the metadata is generated after the fact from the underlying data file. This post-upload metadata can be added by manual curators, who examine the file and its metadata to determine its self-consistency. Curators often standardize the metadata associated with a file onto a specific ontological vocabulary, to make searches through the database more consistent. Derived metadata can also be added to the record by automated processes which assess each new piece of data against quality control metrics.
The challenge that preparing such a data repository presents is that the data and metadata need to be coordinated with each other, but are usually stored in separate places. The files with data are typically stored in a hierarchical directory structure, while the metadata often resides in a database, with pointers into the data file directories to associate the metadata with its data.
The object store solves this problem by storing the metadata with the data files themselves. An object in an object store can have a large amount of key-value metadata associated with it, along with the data in a file.
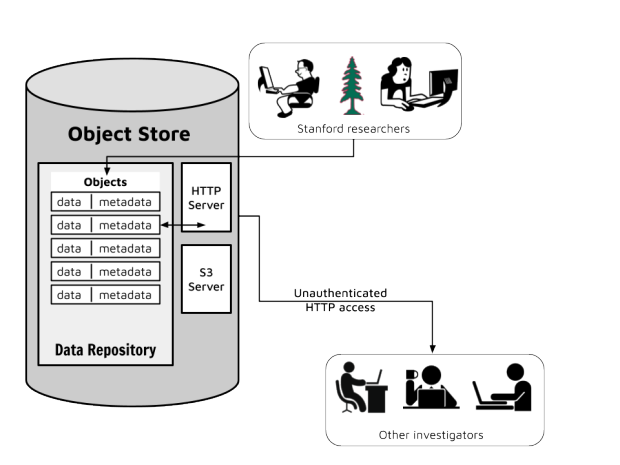
The figure above shows schematically what this use case looks like.
In this diagram, the Stanford researchers place the data they want to share publicly in objects in the object store. These objects contain the data that they are sharing together with metadata about that data. For example, if the data were FASTQ files from a sequencing run, the metadata would be information like read length, the species of the sample, and reagent concentrations. The object store would then share these objects with “Other investigators” who need this data for their work, via normal, unauthenticated HTTP access. The URLs for the objects are generated automatically, so no effort needs to go into setting this scenario up, other than declaring the objects as world-readable.
Restricted-access collaboration
Because of the multidisciplinary nature of many areas of biomedical science and the number of resources required to tackle large projects, many scientific investigations are conducted between labs, between institutions, and/or within consortia. Examples of collaborative efforts between institutions within consortia are the Center for Excellence in Stem Cell Genomics, the Undiagnosed Diseases Network, the ENCODE project, and the ClinGen Resource. To work efficiently together, these disparate groups typically need to share files and datasets, but to maintain data security, this sharing must occur exclusively between the member organizations, and not with the Internet at large.
The options for setting up this type of file sharing all have significant downsides. The easiest thing to do is to give one of the collaborators login access to the servers of the other, but this method gives the outside collaborator access to more of the sharing collaborators’ systems than the situation calls for, and, in the case of UNIX machines, setting the group permissions on the shared files to include the outside collaborators can be very clumsy, since every file can be in only one group. One side can set up a high-speed sharing server like Globus or Aspera, but these solutions are hard to configure and, in the case of Aspera, very expensive. One collaborator can upload the shared data to the cloud for the other to download, but that download by the receiving collaborator will incur charges to the transmitting one, on top of the storage charges for the data while it waits to be downloaded.
The object store provides a solution to the problem of collaboration sharing. The ability to apply fine-grained access control to the objects shared means that it is easy to configure the permissions so that only the needed individuals can download the objects shared. The objects can be exposed as URLs, so they can be downloaded by any browser, without requiring any special client software. And, in the case where an authenticated download is inconvenient, the object store can generate time-limited URLs which are active for only a few hours.
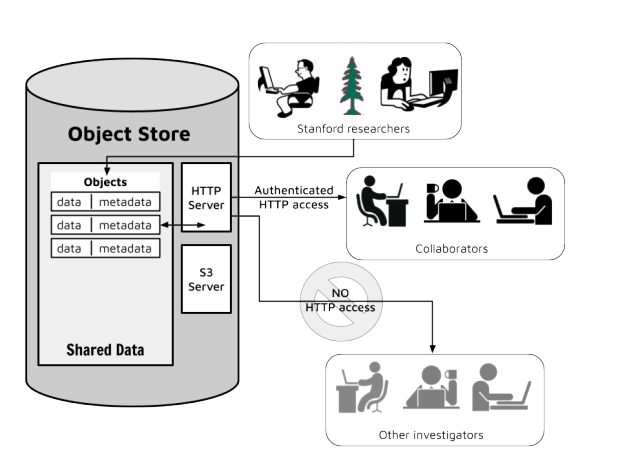
The figure above displays this use case in a schematic.
In this scenario, when Stanford researchers want to share data with the team that they are collaborating with, they upload it to objects in the object store, and set the sharing permissions to the members of that team. Those collaborators can then authenticate themselves to the object store’s HTTP server, and download the data. Other investigators outside of the consortium who may have the URLs for the data shared in this way will NOT be able to access the data.
Mandatory data sharing
In the modern age of easily sharable Big Data, NIH researchers are under pressure from a variety of institutions to make their data available publicly. Many scientific journals, like Cell, Blood, JAMA, and BMC Ecology and Evolution, require that authors make available the data included in their papers as a condition of publication. Also, most NIH grant applications require that the investigator include a data-sharing plan, which requires the distribution of all data from funded research that does not compromise individual subjects' rights and privacy, regardless of whether the data have been used in a publication.
For projects where data distribution is not the goal (unlike the public sharing use case), the need to share the results of an investigation can be challenging. Often, the location of the files during acquisition and processing is not an appropriate place from which to share them. Because of the adherence to dbGaP security guidelines, data on our GBSC cluster at Stanford cannot be shared with a simple webserver attached to our main HPC storage.
This object store enables investigators to store the bulk of the data on this instrument, where it can be accessed through public URLs. They can then put up a lightweight webpage for data sharing (e.g., on a laboratory website, wiki, or on Github) which can then structure the data access, with URLs which point to the instrument. The creation of a data sharing website to fulfill institutional requirements then is now easy and efficient.
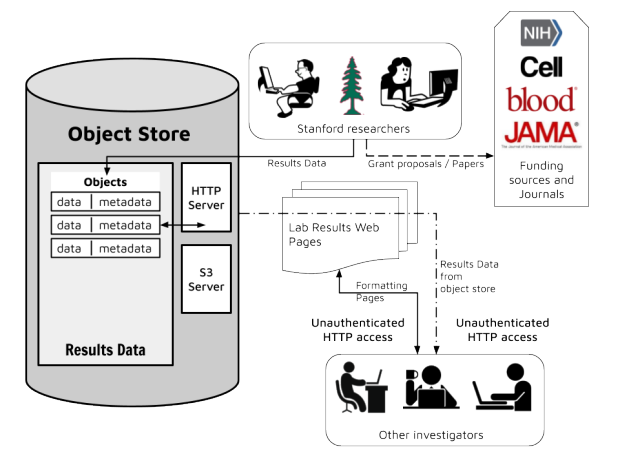
The figure above illustrates this use case graphically. Upon the publication of their work or the completion of a grant, Stanford researchers place their data and related metadata in objects on the object store, and set the objects to allow them to be shared publicly. They then structure this data with separate web pages which contain URLs which point to the object store. Investigators, journals, and funding sources can then go to the structured user-facing web site and download the shared data from the object store.
Sharing to web applications
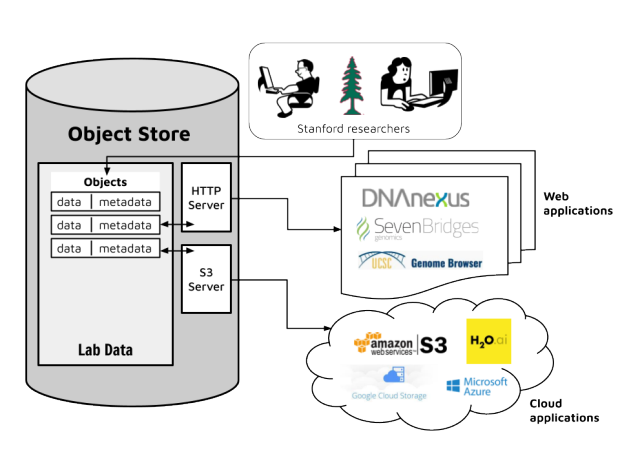
With more software being accessible remotely, either via the web, the cloud, or other server technology, many of these packages are accepting URLs to upload data into their systems. Examples of such packages which accept HTTP URLs for data upload are:
- UCSC Genome Browser
- Ensembl Genome Browser
- SViewer : NCBI Sequence Viewer
- GBrowse: Generic Genome Browser
- DNAnexus - allows analyses on sequencing data in the cloud
- Seven Bridges Genomics - allows analyses on sequencing data in the cloud
Also, a few packages are also accepting S3 URLs, allowing data to be loaded from cloud storage. One such package that has been valuable to NIH investigators is the data mining package H2O. H2O allows a wide range of data science analytics, similar to the R statistical package, but reimplemented to better handle the special problems of very large datasets. Since H2O can directly read and analyze S3 data, a copy of the data is not needed in high performance storage, allowing for cost reductions for researchers.
But being able to associate a URL with data in our current cluster is not feasible. Because of the adherence to dbGaP security guidelines, data on our GBSC cluster at Stanford cannot be shared with a simple webserver attached to our main HPC storage. Similarly, providing an S3 URL would require uploading the file into the cloud.
The instrument solves these problems. It can serve its objects via HTTP or S3 protocols, allowing uploads to these remotely run software packages.
The figure above shows this use case schematically.
A Stanford researcher who wants to upload their data to one of these remote packages creates an object for that data in the object store. They then connect that object via HTTP or S3 to the remote site, which then uploads the data for visualization or analysis.
Object Store FAQs
Is the object store available for research use? Yes. You can request for access to the object store by filling out this form. If you have any questions about the service, send an email to scg-action@lists.stanford.edu .
Who can use the object store? The GBSC services are available to all biomedical researchers at Stanford and affiliated organizations.
Is there any cost to using the object store to share my data? No. The object store is funded by the NIH and available for Stanford researcher use at no charge.
Can I use the object store to archive/backup my data? No. All data that is on the object store must be shared with someone, either publicly or by authentication.
Object Store System Details
Specifications

ECS Object Store
Object Store Configuration Summary
The object store is a EMC Elastic Cloud Storage (ECS) U1600/U400T. This object store features:
- 1.65 Petabytes of usable storage
- 280 x 8 Terabyte SAS Drives
- Empty slots available to expand to a total of 5.6 Petabytes
- 16 file servers for high-throughput
- Multiple 10Gb Ethernet interfaces for parallel access
- ECS Software supporting Amazon S3 and HTTP protocols
This object store is integrated into GBSC's SCG computing cluster and meets moderate risk compliance requirements along with dbGaP compliance requirements.