Curation Application for Disease Database (CADD)
CADD is a secure web application based on the SCIRDB platform that enables research groups to identify and curate program-driven databases containing core modules that include patient demographics, diagnosis, staging, metastasis, treatment courses, and related treatment regimens. Additional modules can be developed as needed.
CADD Features
Patient Identification
Data managers can use and customize patient identification features to discover new research patients by providing physician name, pathology site codes and keywords to be required in clinical reports all within a specified time period.

Registry Maintenance
Once identified patients have been added into the research cohort, users can leverage information from notification pages to retrieve data related to patients’ last Stanford visit, follow-up dates, newly available reports, and death date reports to manage the continuous process of curating research-friendly data.
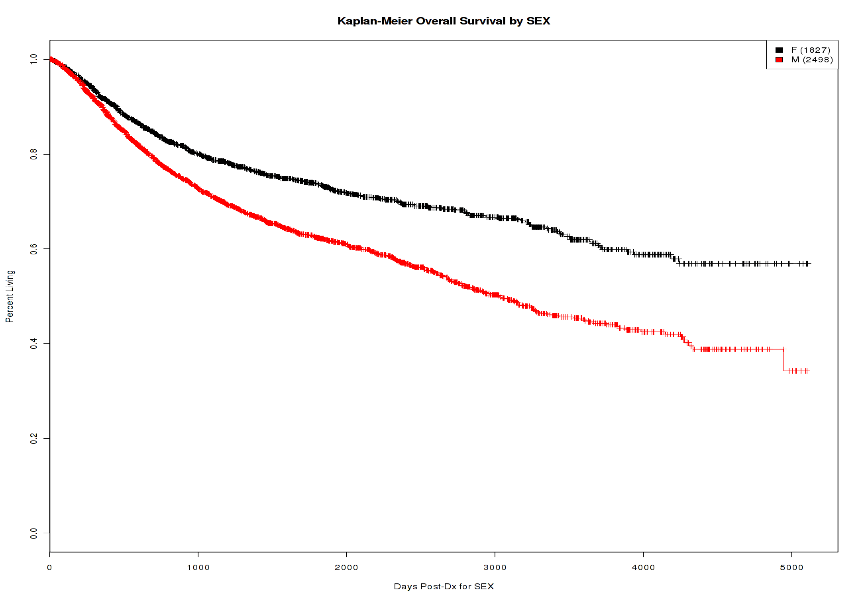
Data Analysis and Collaboration
All the curated research datasets can be integrated with the R Shiny application for in-depth analytic data views that are sliced and diced by curated data attributes. The data can then be extracted for collaborations with outside institutions.