A new SHC Clarity for Stanford School of Medicine
A unified TDS architecture
TDS delivers a new solution for SHC Epic Clarity data for Stanford School of Medicine research use. This new solution replaces a legacy architecture that ran between 2008-2020.
Aug 21, 2021: For the last dozen years, Research IT had maintained a parallel workflow in Stanford School of Medicine (SoM) datacenter for generating a copy of SHC Clarity for research use. This workflow required Research IT staff to operate the Epic Clarity Console on nightly incremental updates sent by SHC team via SFTP. This workflow was high maintenance.
In FY21, Research IT team collaborated with our TDS counterparts to re-architect the solution. The new solution delivers a) complete data, b) high fidelity data, c) low latency data and, d) is less resource intensive to maintain. The new solution went into effect in Aug 2021 after 4 month of intensive testing.
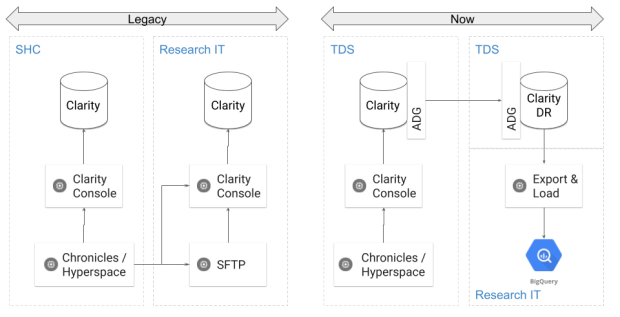
In this new solution, we leverage the SHC Clarity Disaster Recovery (DR) node in a resourceful manner. We add an Oracle Active Data Guard license to make the DR database readable. Subsequently, we extract data from Clarity DR server to a compressed AVRO format and then push the AVRO payload to STARR data lake on Google Cloud Platform (GCP). In GCP, we leverage AVRO support from within BigQuery to regenerate the Clarity.
It takes <12 hrs to extract and push all Clarity data (~3 million patients with clinical text, flowsheets and more) to STARR on a 32 vCPU server with 64 GB RAM.
Learn more:
- Active Data Guard license (more)
- Extracting data from Oracle in AVRO format (Research IT manuscript, Supplementary Section 3, Database Technologies)
- Loading data in BigQuery from AVRO (more)
We are grateful to all team members who helped us run the legacy solution for a dozen years. As SHC Epic got bigger and updates more frequent, the legacy solution got harder and harder to maintain. On behalf of our researchers, Research IT thanks all of you who were part of managing this legacy workflow, for your everyday sacrifices, for spending vacations babysitting the servers, storage, network, database, oracle bugs, log shipping, Clarity console jobs, ETLs and much more.

