Metadata prediction results published in BioCuration Virtual Issue in the journal Database.

Frequent terms in the unstructured text values of GEO metadata values. This figure shows terms which are frequently used in the unstructured elements of the GEO dataset. Colors and size correspond to the frequency of a term.
Overview
Our work in the context of the CEDAR, the Center for Expanded Data Annotation and Retrieval, on developing machine learning models to predict Metadata has been accepted for publication in a special issue of Database. In this work we describes a framework to predict structured metadata terms from unstructured metadata to improve the quality and quantity of metadata for the GEO microarray database. We developed two approaches for metadata prediction: TF-IDF and Latent Dirichlet Allocation (LDA). We use a Latent Dirichlet Allocation (LDA) model in combination with machine learning methods to effectively predict structured metadata. Our results show that predicting metadata is promising approach `that is likely to be applicable to other datasets and has implications for researchers and practitioners interested in biomedical metadata curation and metadata prediction.
This work is a collaboration between the Gevaert lab and the Dumontier lab in CEDAR. CEDAR is one of in total eleven centers supported by the National Institute of Allergy and Infectious Diseases through funds provided by the trans-NIH Big Data to Knowledge (BD2K) initiative. Read more about the other BD2K centers here.
Results
Our results on the GEO database show that structured metadata terms can be the most accurately predicted using the TF-IDF approach followed by LDA both outperforming the majority vote baseline. While some accuracy is lost by the dimensionality reduction of LDA, the difference is small for elements with few possible values, and there is a large improvement over the majority classifier baseline.
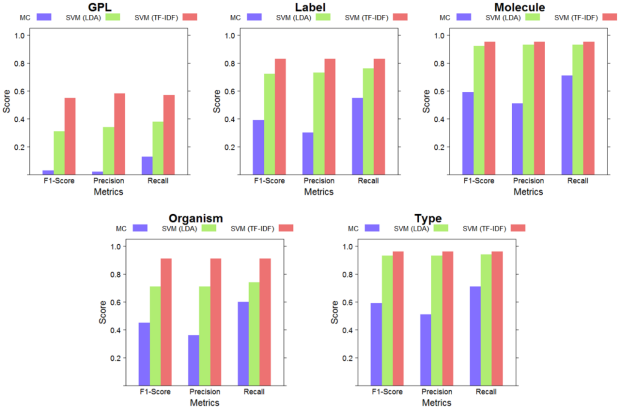
Evaluation Results. This figure shows weighted class averages for precision, recall and F1-Score for each structured element. Results are reported for linear SVM with LDA features, linear SVM with TF-IDF features and for the majority classifier (MC) baseline. While some information was lost during LDA’s dimensionality reduction (by 98%), both approaches performed better than the baseline for all elements.
The best classification results were achieved for the GEO elements with the smallest number of classes. The element with the highest number of classes, GPL, had the lowest absolute scores, but a large improvement over the baseline. During the dimensionality reduction of 98% by LDA, information is lost compared to using the full vocabulary as features for training the classifiers. However, the performance on elements with few values is similar as that of the classifiers trained on the full vocabulary. The baseline classifier is outperformed in all cases, both by the classifiers using TF-IDF features and the classifiers using topic features.
The code used for this project is available here.
Reference:
Posch,L., Panahiazar,M., Dumontier,M. et al. Predicting structured metadata from unstructured metadata. Database (2016) Vol. 2016: article ID baw080; doi:10.1093/database/baw080